Unable to acquire JDBC Connection 에러 오답노트2
이전글)
현재글)
- Unable to acquire JDBC Connection(DHCP lease lost) 에러 오답노트2
✔️ 문제 재확인
어플리케이션의 문제는 아닌듯 보여 VM 장비로 포커스를 맞춰 문제를 다시 파악했다.
여러 VM의 어플리케이션 로그들을 키바나에서 보고 있어서 몰랐는데, 자세히 보니 특정 패턴이 보였다.
각 장비마다 매일 특정 시간대에 connection 에러를 발생시키고 있었다..!!!
즉, 1번 워커노드의 서버는 매일 대약 2시쯤, 2번 워커노드의 서버는 매일 대략 3시 반쯤 등 timeout 오류를 발생시키고 있었다.
열심히 인사이트를 찾아보다가 syslog를 확인하게 되었는데,
# syslog 위치 (나는 무슨 문제였는지 몰랐기 때문에 syslog 내용을 확인 하였다.)
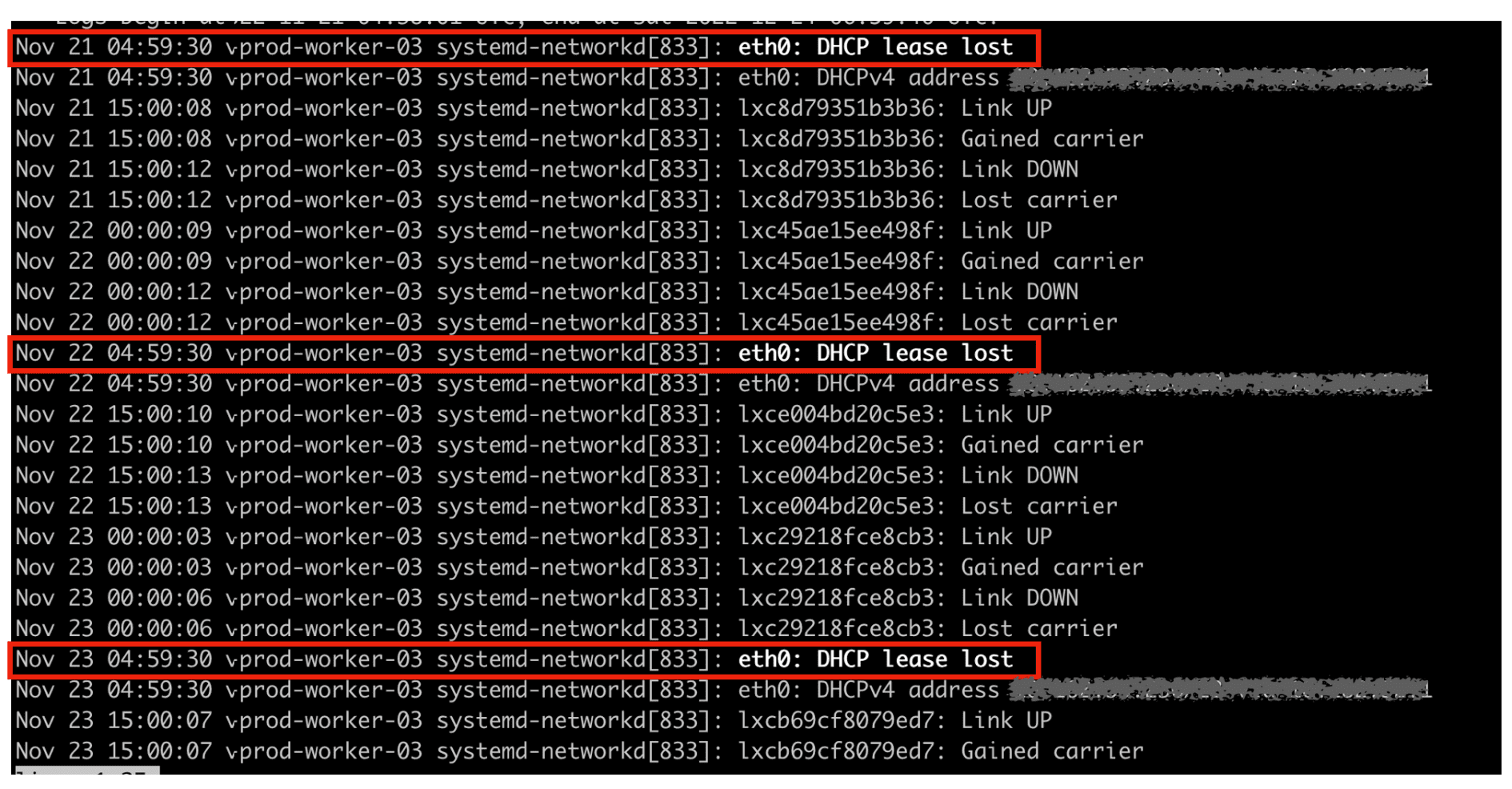
$ ll /var/log/syslog*아래와 같이 systemd-networkd 에서 eth0: DHCP lease lost 가 발생이 되고 있다는 걸 알게 되었다.
참고) systemd-networkd 로그만 확인하는 방법
$ journalctl -u systemd-networkd즉!! VM에서 커넥션 종료를 시켰고, 어플리케이션 서버에서는 이를 전혀 감지하지 못하고 dead connection 을 가지고 요청을 수행하려다가 결국 타임아웃 에러가 발생 한 것이다.
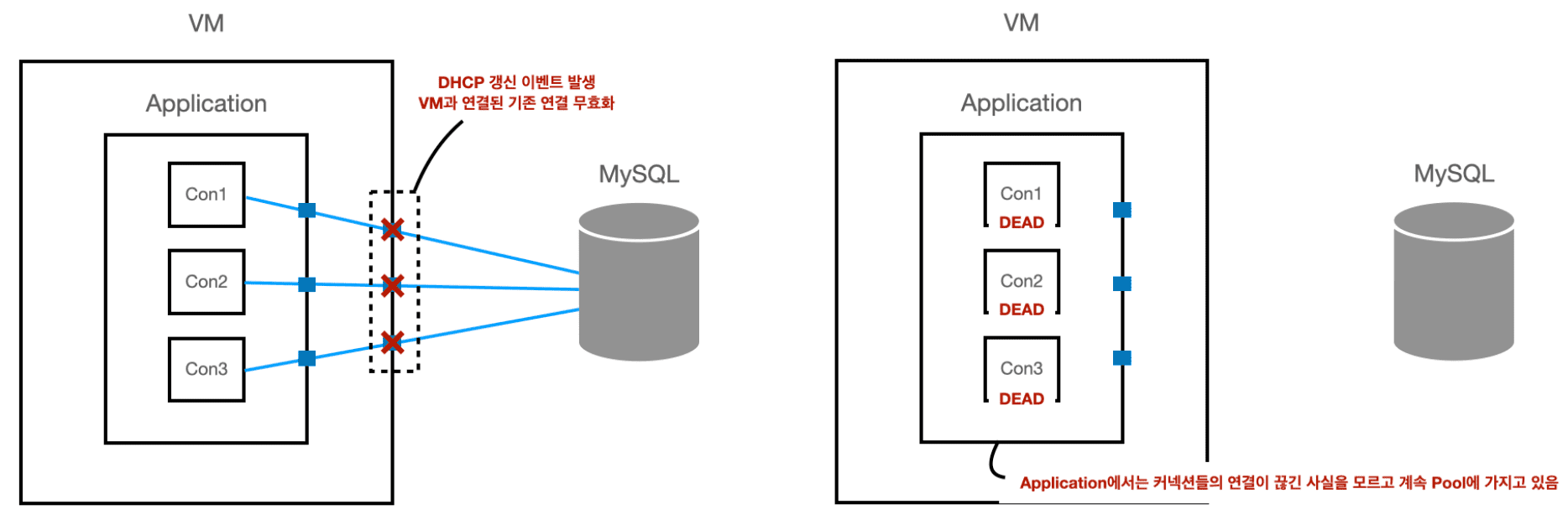
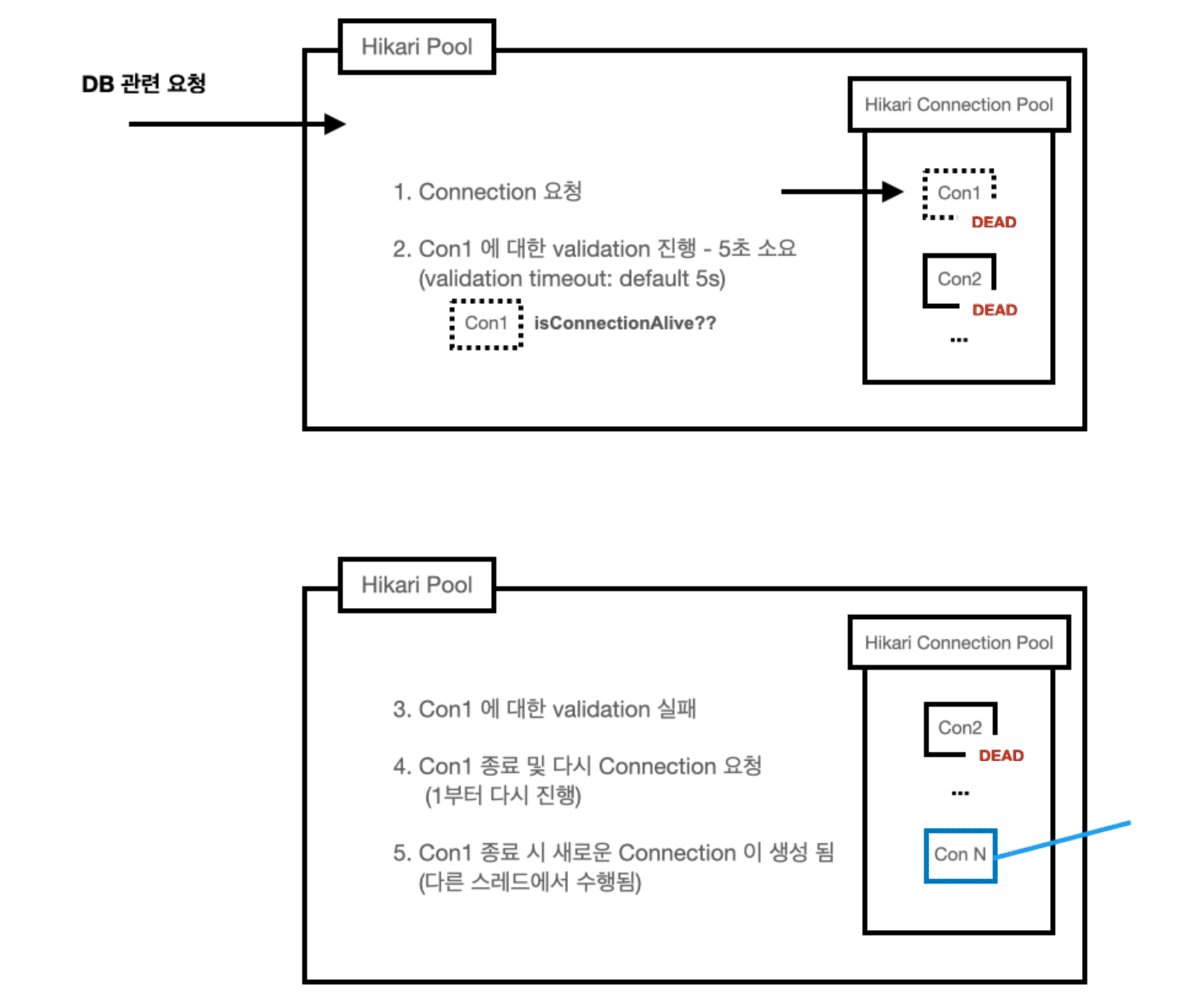
Hikari Pool 에서 타임아웃 에러가 발생한 이유는 아래와 같다.
- DB 수행이 필요한 요청이 들어온다.
- Connection Pool에서 커넥션을 가져온다.
- Hikari CP에서 가져온 커넥션에 대한 validation을 진행한다. 이때, validation timeout은 default로 5초이다.
- DHCP lease lost 때문에 dead connection으로 validation에 실패하게 되고(5초 소요)
- 해당 커넥션을 종료시키고 다시 2번부터 수행한다. (커넥션을 종료하면 Pool의 개수를 맞추기 위해 hikari 의 housekeeper 스레드에서 새로운 커넥션을 생성하여 pool에 넣는다.)
- 2-5번을 반복하며 vaildation을 하는데 시간을 계속 소비하여 available 한 커넥션을 찾지 못하고, 결국 db connetion timout 에러가 발생하게 된다. (기본 db connection timeout 시간은 30초이다. : spring.datasource.hikari.connectionTimeout )
DHCP 현상에 대한 인프라팀 답변으로는, 생성된 VM 들은 DHCP 기반으로 IP를 할당받도록 되어 있었고, DHCP 갱신을 24시간 주기로 수행하며 갱신하는 시점에 순간 네트워크 설정이 reset 되면서 기존 연결이 무효화가 되어 DB처럼 커넥션을 연결해놓고 사용하는 경우에는 해당 문제가 발생했다고 한다.
✔️ 문제를 확인 했으니, 조치를 해보자
ubuntu 18.04 기준으로 /etc/netplan/50-cloud-init.yaml 파일에 critical: true 필드를 추가 후 apply 하면 된다.
1. 설정파일 수정
# /etc/netplan/50-cloud-init.yaml
network:
ethernets:
eth0:
dhcp4: true
critical: true #추가
match:
macaddress: fa:...
set-name: eth0
version: 22. 설정파일 적용
$ sudo netplan apply당일에는 DHCP 갱신이 이미 발생이 된 후라 다음날 확인을 해보니, 더이상 connection 오류가 발생하지 않았다.
어휴! 이슈 해결하느라 고생한 나 자신 칭찬한다.
참고)
- dhcp란?
https://jwprogramming.tistory.com/3 - dhcp ip 대여시간
https://points.tistory.com/15 - dhcp message type
http://www.ktword.co.kr/test/view/view.php?m_temp1=5419&id=1244 - 라우터 vs 공유기
https://m.blog.naver.com/PostView.naver?blogId=msnayana&logNo=80105365859&proxyReferer= - configuring dhcp lease
https://serverfault.com/questions/1022612/configuring-dhcp-lease-when-using-systemd-networkd-on-ubuntu-18-04-server