프로메테우스 삽질기
1. 무엇을 표현하고 싶었는가?
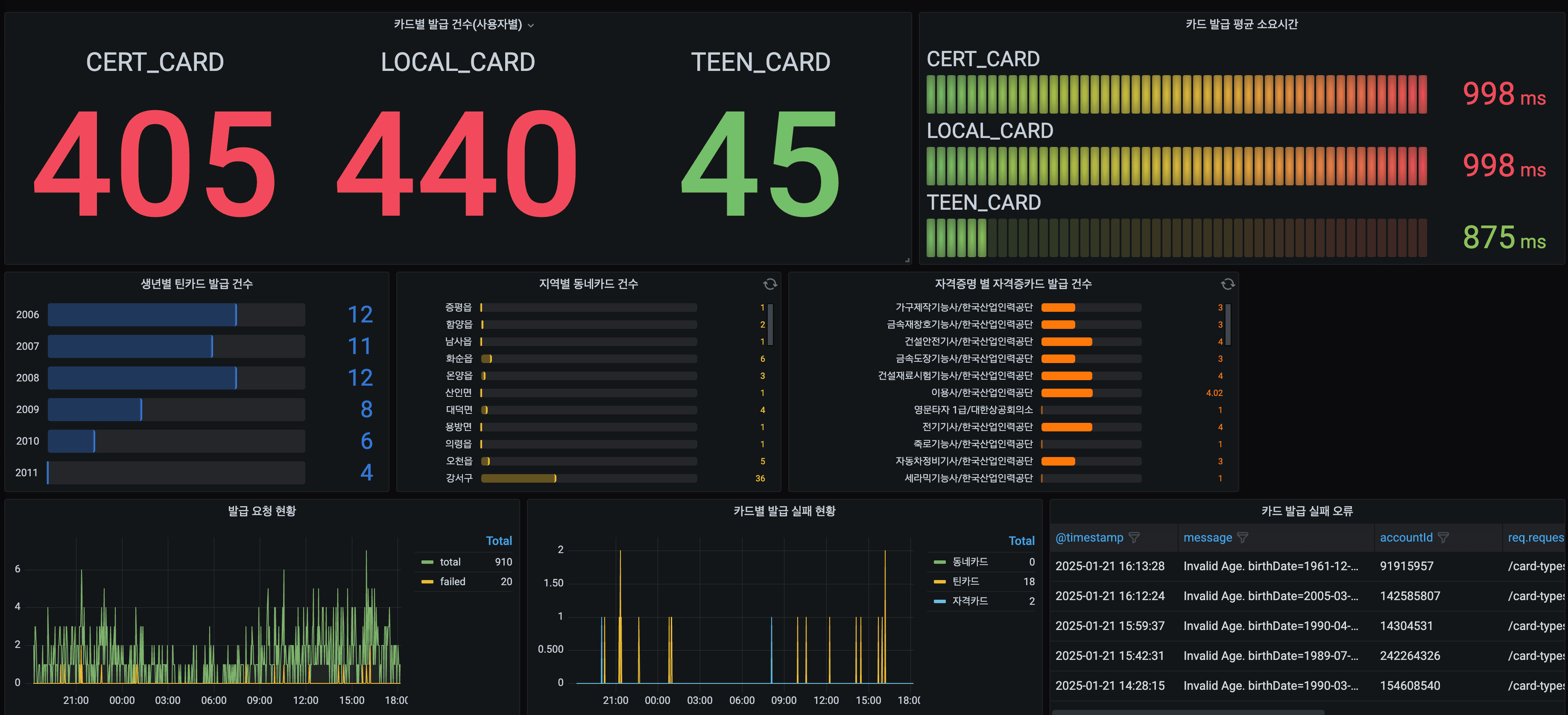
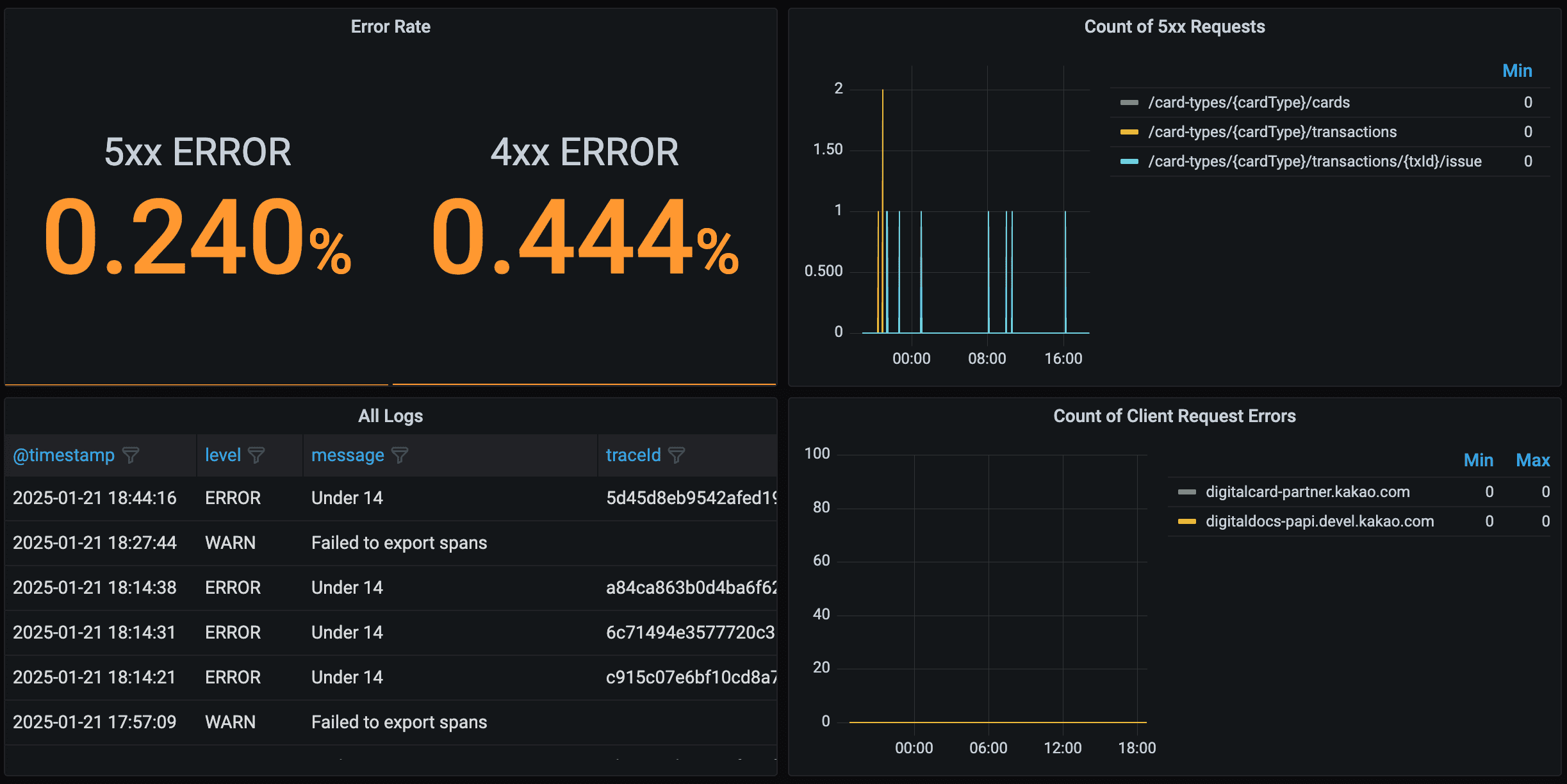
✔︎ 서비스 지표
발급 건수, 카드 종류별 건수, 실패 건수 등 카드 발급 현황에 대한 지표 구성
무엇을 고려 하였는가?
- 카드별 발급 건수 표시로 카드 선호도/수요 분석
- 카드 발급 실패에 대한 원인 파악
✔︎ traffic (트래픽)
서버로 들어오는 총 요청에 대한 파악을 위해 지표 구성
무엇을 고려 하였는가?
- 부하 확인
- 리전별 요청 비율로 리전 이상 현상 감지


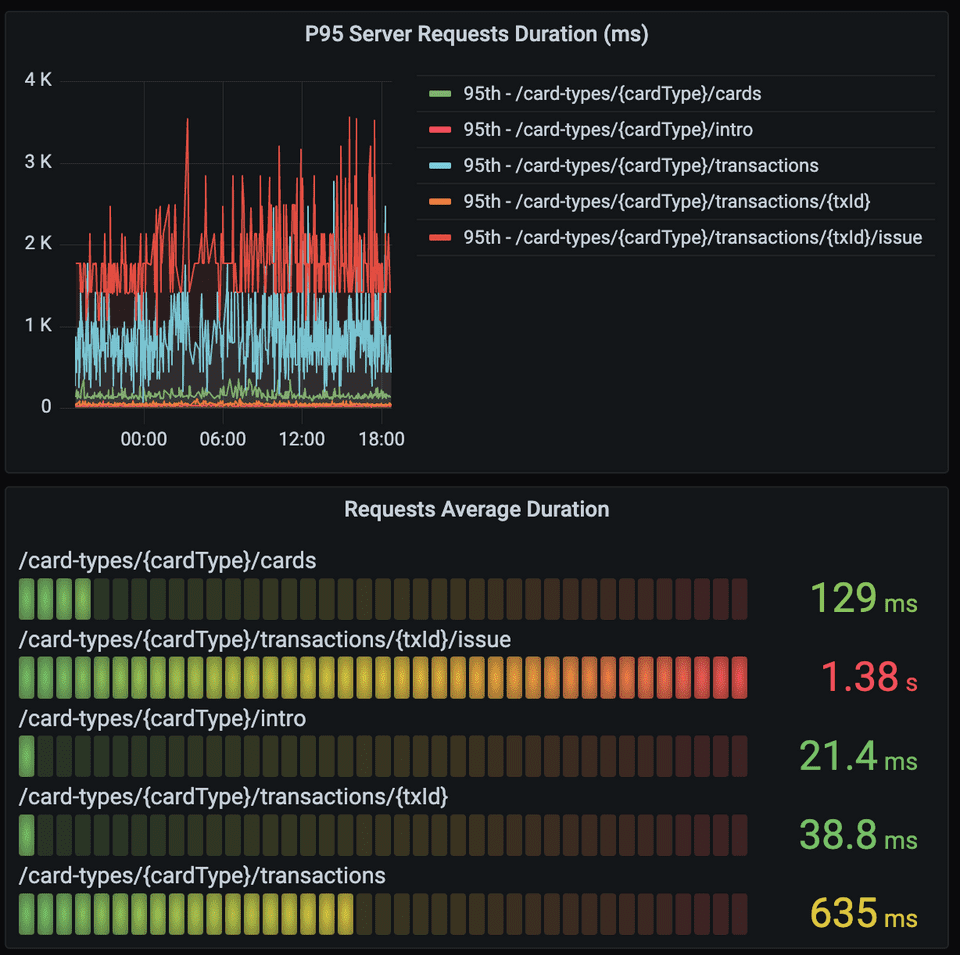
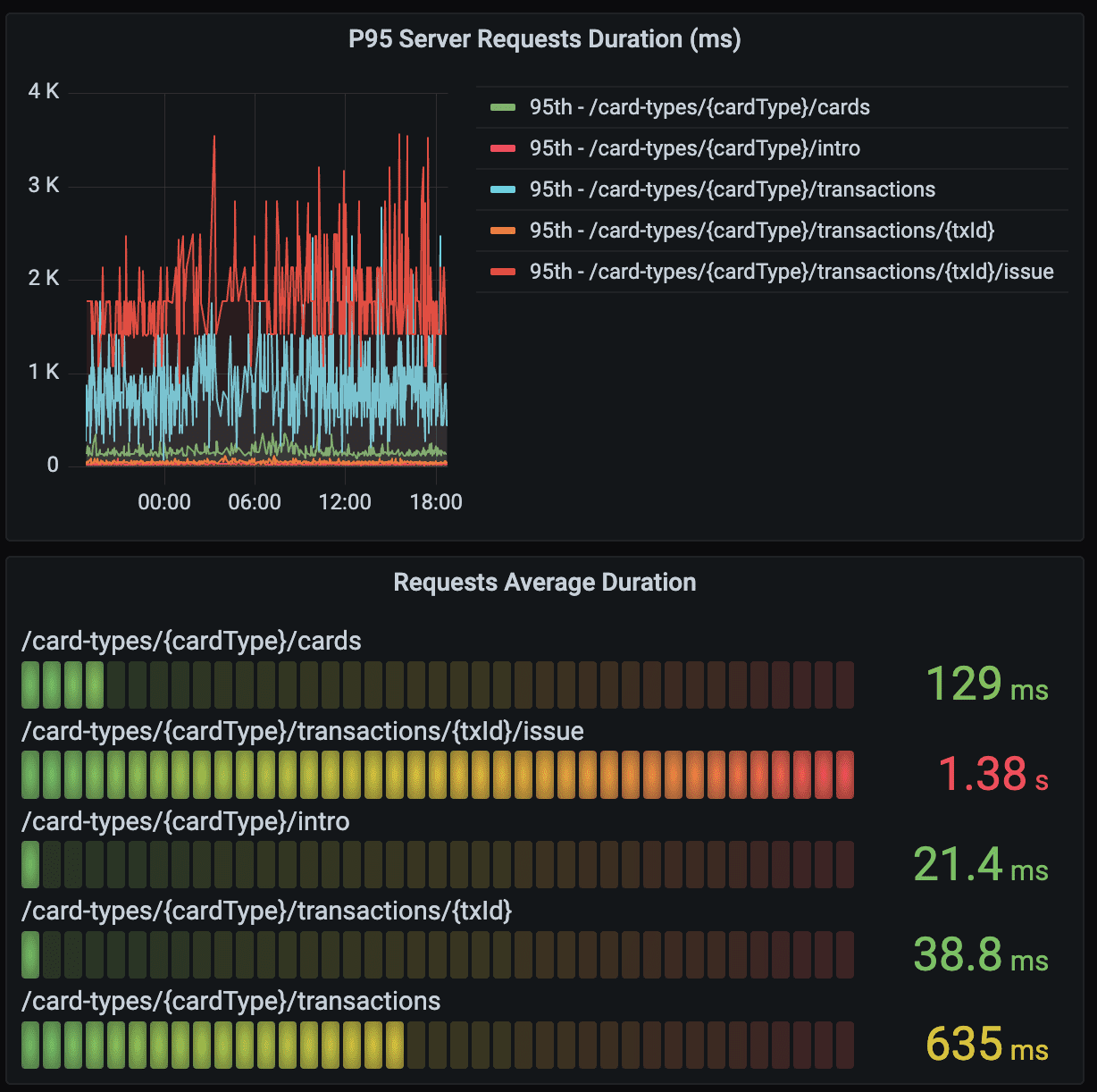
✔︎ atency (지연)
응답 시간에 대한 파악을 위해 지표 구성
무엇을 고려 하였는가?
- 일반 사용자가 체감하는 응답 시간 - P95, 성공 응답 평균 시간
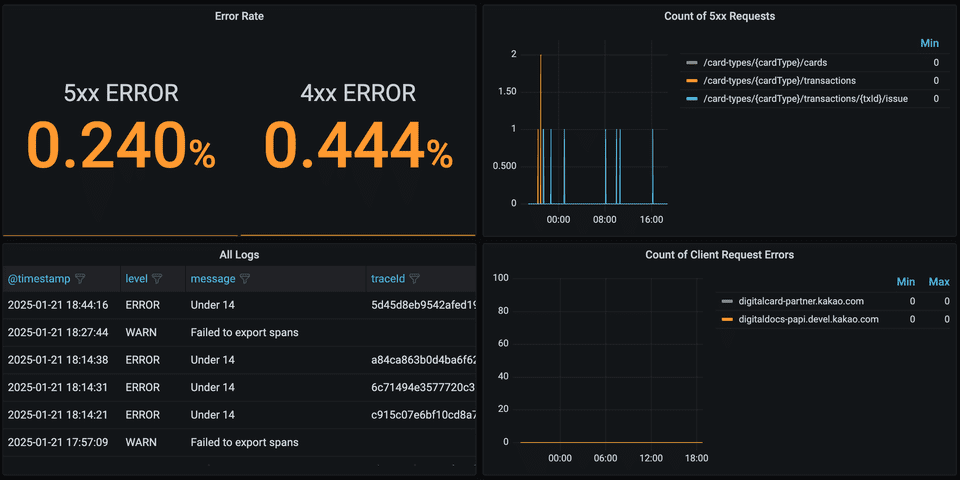
✔︎ errors (오류)
에러 응답에 대해 파악하기 위한 지표 구성
무엇을 고려 하였는가?
- 5xx/ 4xx 에러율 확인에 따른 이상현상 감지 및 에러 메시지 확인
- 연동서버 이상현상 감지
2.︎ 무엇이 어려웠는가? (왜 안맞나?, 표현이 어려웠던 것은 무엇인가? …)
2.1. promQL 문법의 이해
✔︎ http_server_requests_seconds_count{uri="/api"}[5m]
http_server_requests_seconds_count메트릭을 사용할꺼고,- uri가 “/api” 인 데이터만 필터 할꺼고,
- 지금 시점부터 5분 전까지의 데이터를 추출
- 현재 2dzzv 파드에서 발생한 이벤트 총 카운트는 2건, cxw24 파드는 1건


✔︎ increase(http_server_requests_seconds_count{uri="/api"}[5m])
- 위 결과에서 증가건수 계산
- 시간에 따른 카운트 변화가 없으므로 증가는 0


2.2. 프로메테우스에서 수집하는 메트릭 중에 무엇을 사용했나?
✔︎ http_server_requests_seconds_count
- 서비스 시작 이후의 누적 요청 횟수


✔︎ http_server_requests_seconds_bucket
- 요청 응답 시간의 분포


2.3. 지표를 표현하기 위해서 어떤 함수를 사용했는가?
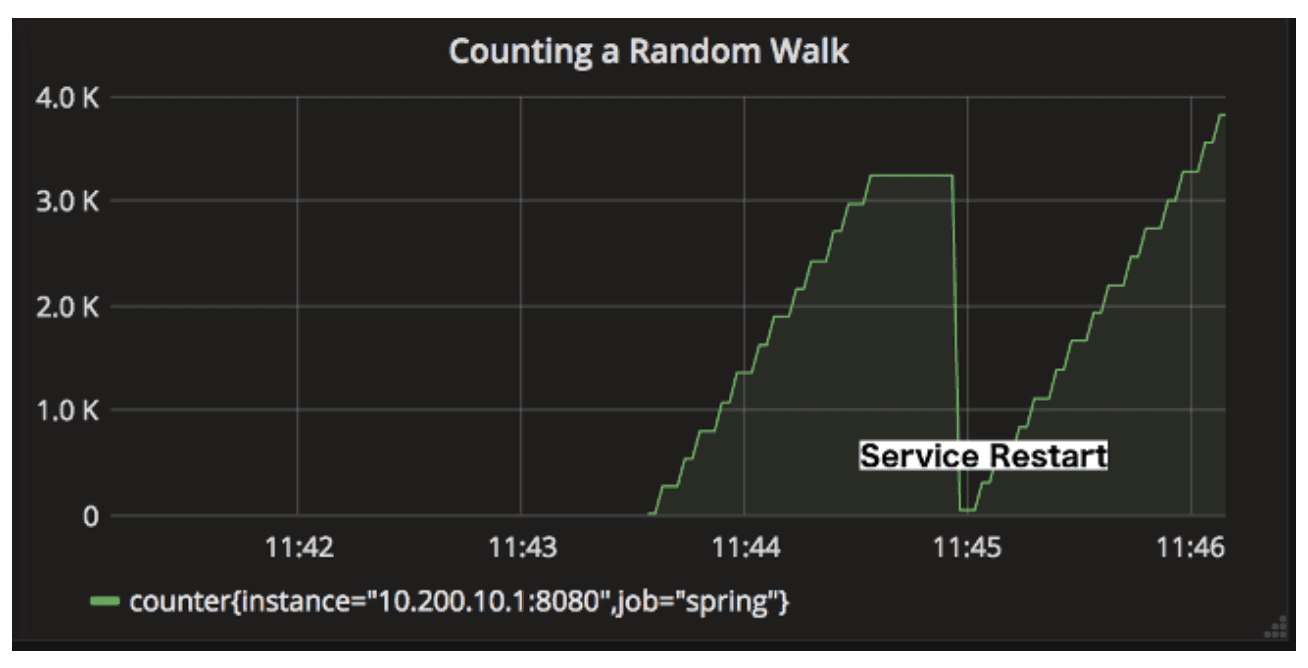
✔︎ 단순히 카운터로 누적 수를 계산하면 될꺼 같은데, 왜 increase, rate 를 사용했을까?
- 프로세스가 재실행 될 경우 해당 메트릭의 값이 0으로 리셋된다.
- increase, rate 함수는 리셋을 스스로 감지하여 이전 상태를 보정하여 증가량을 계산한다.
-
아래와 같이 카운터의 결과가 나왔을때, 각 increase의 값을 더해서 누적 수를 계산한다.
시간 누적수 증가 13:00:00 100 13:01:00 200 -> 100 13:02:00 300 -> 100 13:03:00 150 -> 0 (리셋 이벤트 발생) 13:04:00 0 13:05:00 0 13:06:00 50 -> 50 13:07:00 100 -> 50 -------------------- increase 결과: 300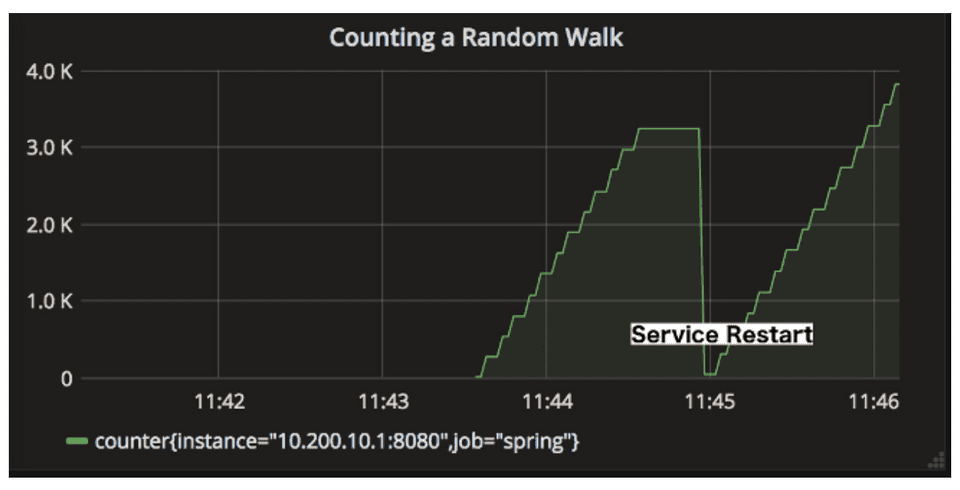
✔︎ increase
- 주어진 시간 범위 내에서 카운터 값의 총 증가량
-
5분동안 요청된 총 증가량
increase(http_server_requests_seconds_count[5m])
✔︎ rate
- 초당 증가율
-
5분동안의 초당 증가율
rate(http_server_requests_seconds_count[5m])
✔︎ histogram_quantile
- 히스토그램 데이터 기반으로 특정 분위수(예: 50%, 90%) 값을 추정하는 데 사용
-
5분동안의 초당 증가율을 구하는데, 상위 1%는 제외하여 연산한다.
histogram_quantile(0.9, rate(http_server_requests_seconds_bucket[5m]))
✔︎ 왜 소수가 나올까?
- 선형 보간을 수행하기 때문이다.
- 실제 요청이 특정 시점에 몰려 있더라도 일정한 속도로 증가한다고 가정하여 1.009와 같은 소수점 값이 나올 수 있음.
- 보간: 주어진 데이터 사이의 값들을 추정하여 새로운 값을 생성하는 방법
- 참고:
https://promlabs.com/blog/2021/01/29/how-exactly-does-promql-calculate-rates/
https://velog.io/@skynet/Prometheus-rate-%EC%97%B0%EC%82%B0%EC%9D%98-%EC%8B%A4%ED%96%89-%EC%9B%90%EB%A6%AC
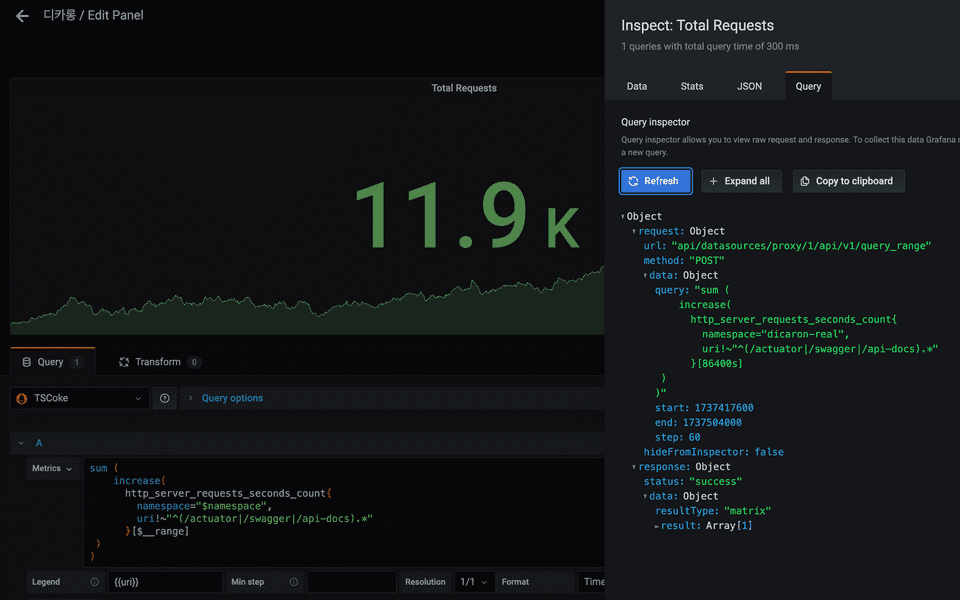
2.4. 그래서 그라파나에서 어떻게 사용하는데?
그라파나에서는 프로메테우스 웹 ui와는 다르게 from, to, step 를 추가 설정한다.
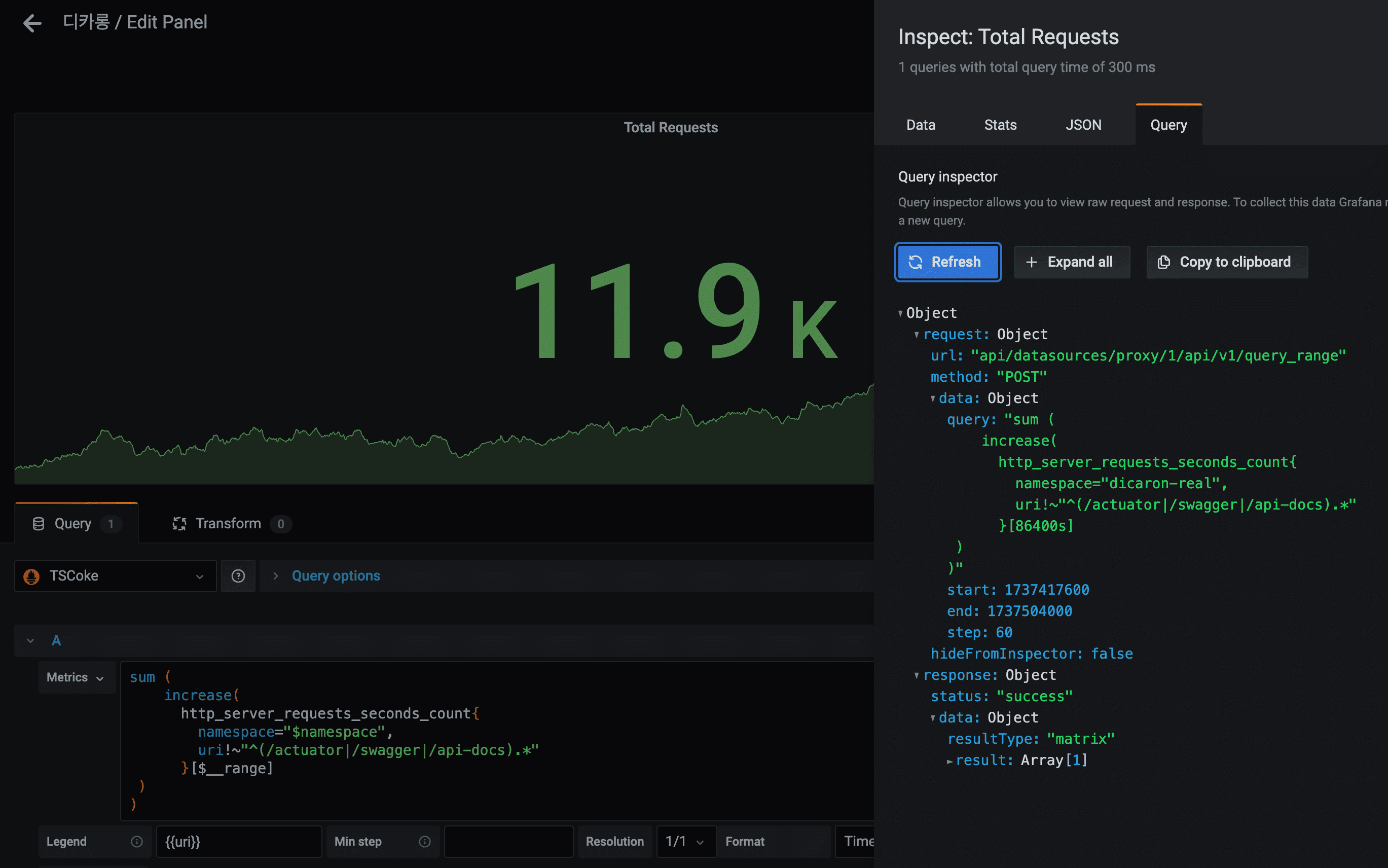
✔︎ from, to(range) 의 총 수치 나타내기
- 그라파나에서 지정한 시간 범위의 총 수치를 표현하기 위해서는 $__range 변수를 사용한다.
✔︎ 시간 흐름에 따른 수치 나타내기
- 시간 흐름에 따른 수치를 표현하기 위해서는 [계산시간범위:step] 을 사용한다.
-
아래 쿼리는 (sum by (uri) (rate(httpserverrequestssecondscount{namespace=“$namespace”, uri!~”^(/actuator|/swagger|/api-docs).*“}[1m:1m]))),
-
- 그라파나에서 지정한 시간 범위(24h)를
-
- 1분마다 쪼개 초당 증가율을 구하는데,
-
- x축의 기준을 1분 단위로 가져간다.
-
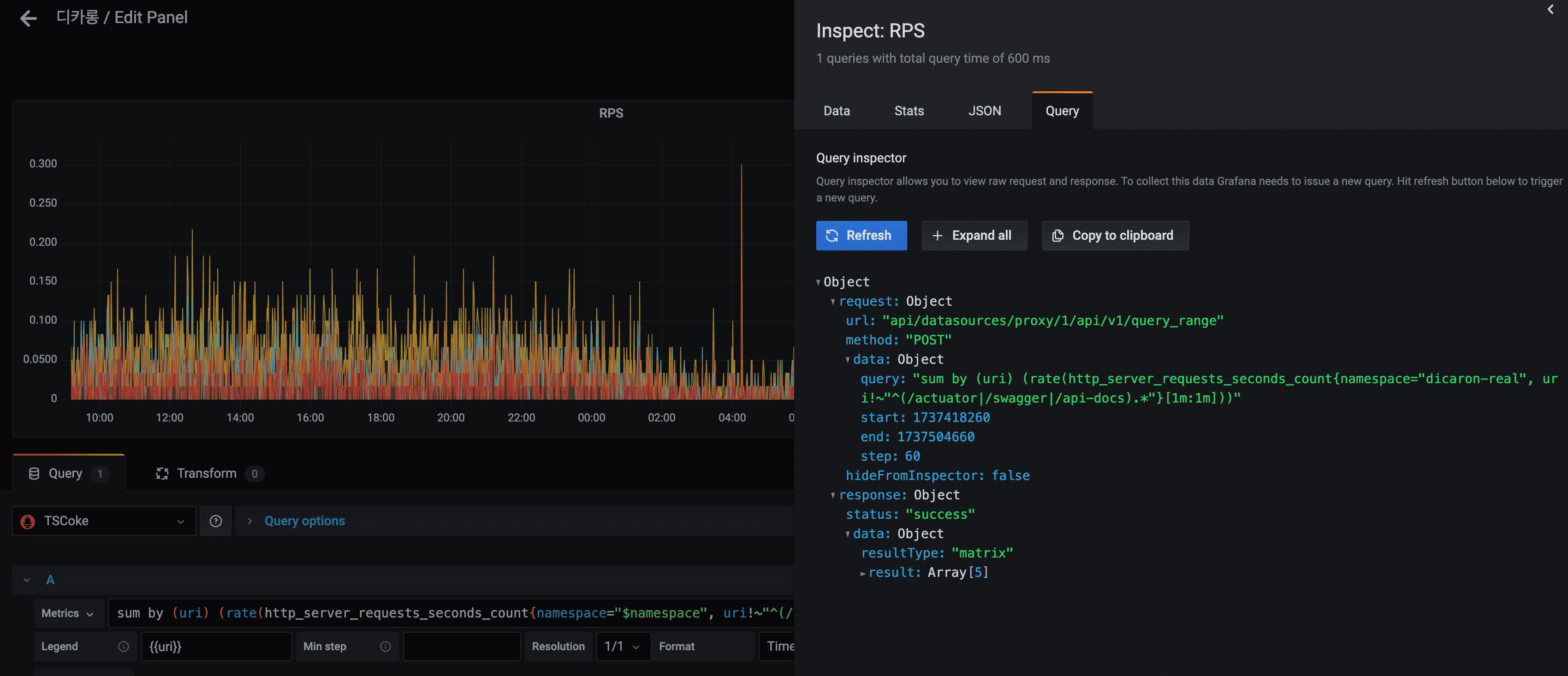
- 두 포인트간 사이는 1분
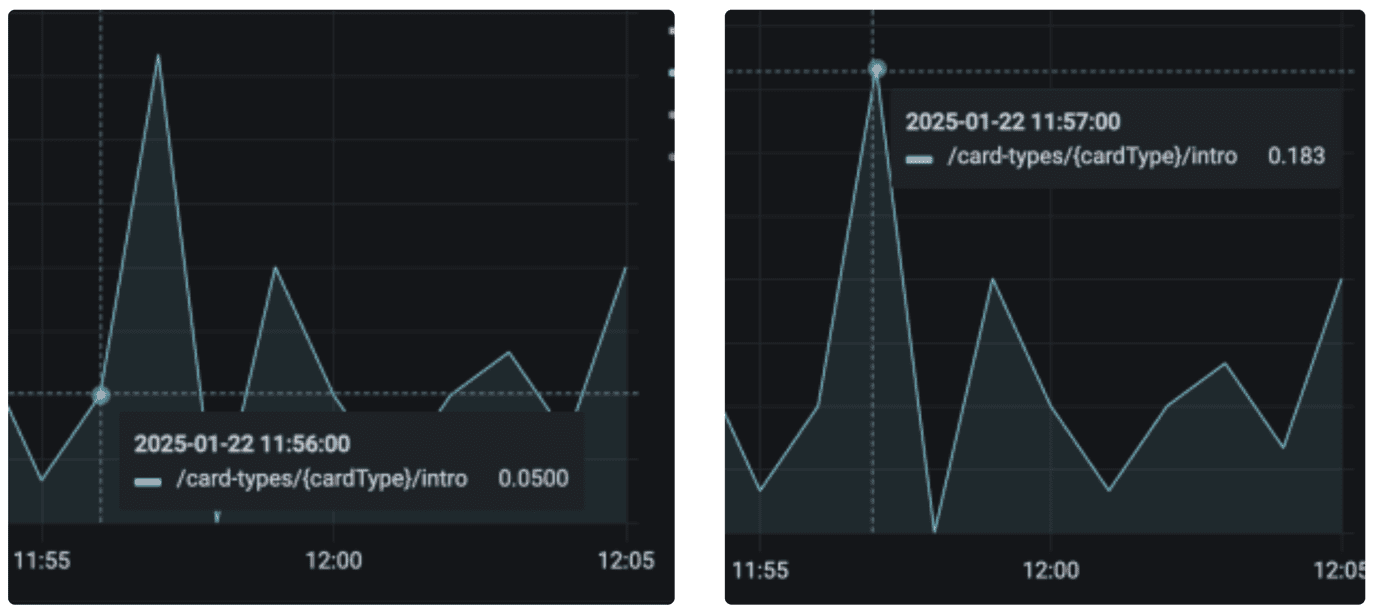
2.5. 왜 기대한 값이 나오지 않을까?
- rate, increase 를 쓰면 총 건수에 대한 값이 정확히 노출 될 줄 알았지…
✔︎ 소수로 나타나지는 결과
- 위에서 설명한 것 처럼 보간법 때문에 정수가 아닌 소수로 나타날 수 있다.
✔︎ 카운터 리셋 감지시에 기대와 다른 increase 결과
-
롤아웃 후, 각 파드 별로 1건의 요청이 들어왔을때, increase 의 결과는 1이 아니라 0으로 표시가 된다.
- 카운트가 0→1 로 변하는게 아니라 NaN → 1로 변화하는걸로 예상
- 때문에, 정확한 총 건수에 실패하며, 파드 수가 많을 수록 누락되는 건수가 많아 진다.
http_server_requests_seconds_count{uri="/card-types/{cardType}/intro"}[5m] 결과
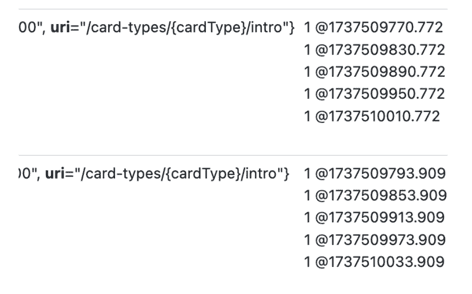
increase(http_server_requests_seconds_count{uri="/card-types/{cardType}/intro"}[5m]) 결과

2건의 요청이 들어왔을땐?
http_server_requests_seconds_count{uri="/card-types/{cardType}/intro"}[5m] 결과
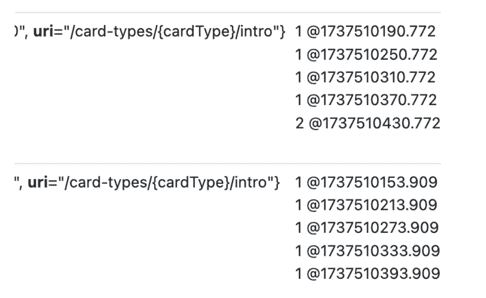
increase(http_server_requests_seconds_count{uri="/card-types/{cardType}/intro"}[5m]) 결과

2.5. 아쉬운 점
- 프로메테우스를 통해 수집한 지표들은 정확한 “건수”를 도출하기 힘들다.
- 실제, 건수가 많은 지표에 10건 이하의 건수 누락은 크게 문제가 안되겠지만, 카드 발급 현황의 경우, 파드 수 만큼 개수가 빠지므로 크게 표시가 남.
- 따라서, 정확한 건수를 위한 지표보다는 현황 및 이상 감지 용도로 적합하다.